31 May

On May 18, I got the opportunity to speak in front of a room full of people that wanted to discover more about Kubernetes autoscalers and how to get to the optimal system configuration.
First of all, I must admit that I was a bit nervous. It was my first time speaking at KubeCon and I wanted everything to go smoothly. There is of course no substitute for preparation. Repetition is essential, not only to improve the content iteratively, but also to grow confidence in your ability to speak in front of a large audience. In the weeks leading to KubeCon, my teammates helped me a lot, by checking my slides, listening to my rehearsals, and providing feedback that I incorporated into my material and my delivery.

In my presentation, I included the results of an extensive tuning campaign Moviri conducted on a real application running on Kubernetes. We used AI to automate the optimization process of a transaction-heavy application by a leading SaaS financial services provider, with the objective of minimizing cloud cost without compromising performance.
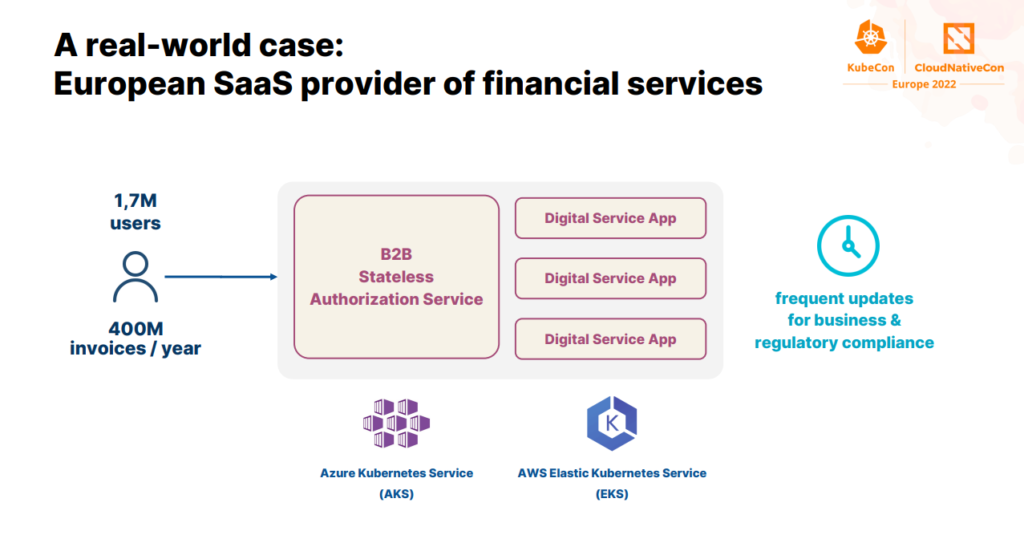
The optimization target we used was a Java-based microservice running on Azure Kubernetes Services, which is in charge of providing the B2B authorization service that all digital services use.
The first thing we did was a load test with the initial configuration of the microservice and by replicating a diurnal traffic pattern, where we discovered an unwanted behavior that was caused by having configured the JVM max heap higher than the memory request. Then we started the AI-powered optimization process, by setting up an optimization goal: minimizing the overall cost of the service running on Azure cloud.
In this study, we considered nine tunable parameters: four Kubernetes and five JVM parameters. All of them were tuned simultaneously to make sure that the JVM was optimally configured to run in the Kubernetes pod. We found the best configuration of the goal given after a few experiments, in less than a day. The configuration provided a 49% improvement on the bill, thus being beneficial even in terms of resilience and performance.
During the optimization study, we found other configurations like the one that reduced costs by 16% (our goal) and displayed a higher improvement in resilience. There was a lower response time peak upon scaling out and the replicas scaled back after the high load phase.
All this was possible thanks to the Akamas AI-powered optimization platform, which we used specifically to conduct this tuning campaign. Akamas was founded as a spinoff of the performance engineering team at Moviri and is now an independent company with which we have a strategic partnership. If you are interested in discovering more about the specifics, you can check out their case study.
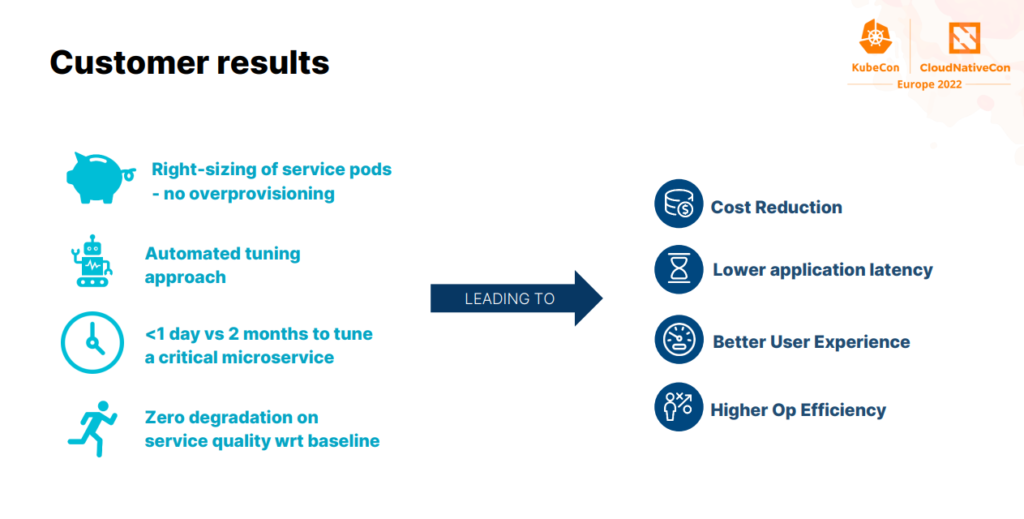
So, what is the key takeaway from my speech? You always have to tune your pods, since K8s won’t do it for you. And the best way to do it is to leverage an AI that could allow you to deal with the complexity of modern applications.
The last speech that I think was particularly interesting and focused on similar topics as mine, was from Vincent Sevel, Architect / Platform Ops at Lombard Odier. His company has been a private bank in Switzerland since 1796 and its main businesses are private clients, asset management, and technology for banking. Their banking platform is a modular service-oriented solution, with approximately 800 application components. A large modernization initiative, both functional and technical, started in 2020.
The goals of Lombard Odier were to optimize placement of pods in a Kubernetes cluster, tune resources on worker nodes, size optimally the underlying hardware, avoid waste, save money, and all this without sacrificing behavior. Definitely complex.
Vincent explained how their application was made, the clusters involved, and showed few use cases. Even though they didn’t finish testing everything and analyzing all their data, they already learned some intriguing lessons. For example, they’ve been surprised by the low CPU recommendation of the VPA and they faced the same JVM startup issues we analyzed in our talk.
