Moviri, Performance Engineering
Establishing digital resilience by embracing Chaos Engineering
14 Mar

What is Chaos Engineering?
The official definition, from the Principles of Chaos Engineering website, describes Chaos Engineering as “the discipline of experimenting on a software system in production in order to build confidence in the system’s capability to withstand turbulent conditions in production”. Put it in simpler terms, Chaos Engineering breaks parts of software, on purpose, to identify failures before becoming outages that impact the system and, eventually, the business.
The goal of Chaos Engineering is to improve the stability and resiliency of your systems, similar to the Performance Testing one. The difference between the two practices is the approach they use. Instead of evaluating the impact of load-related stressful situations, Chaos Engineering allows testing even more failure cases. For example, what would happen to my system if one of my third-party providers of services releases a defect and breaks it down? The two practices are actually synergic, and not disconnected.
Why do companies need to perform Chaos Testing now more than ever?
Companies are moving to the cloud or they are rearchitecting their systems to be cloud-native. This makes their systems more distributed and increases the possibility of unplanned failures or unexpected outages. In fact, sooner or later, failures will happen and it is up to you to anticipate them and mitigate their business impact. This is not an easy task.
Chaos Engineering aims to simplify this task by allowing the identification of potential faults caused by infrastructure, dependencies, configurations, and processes.
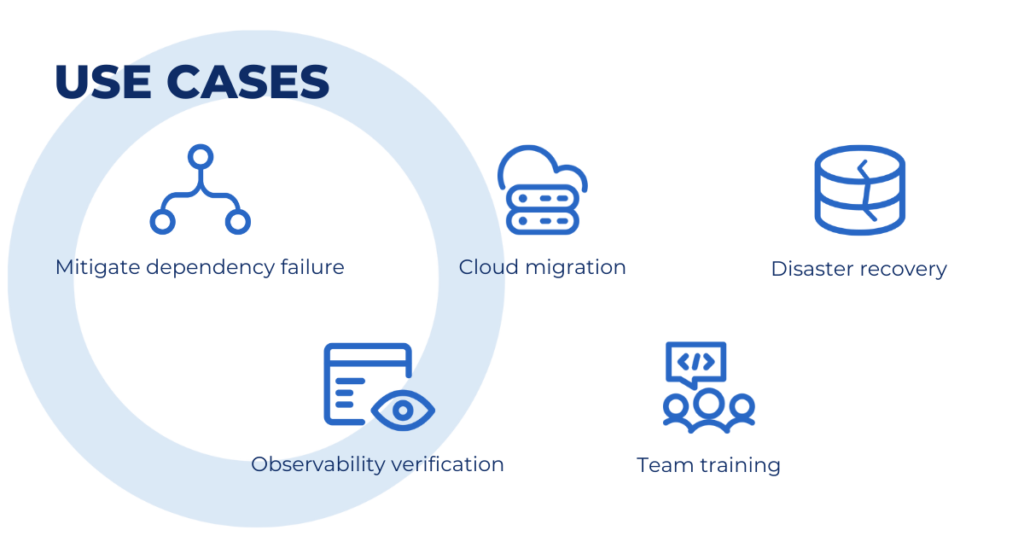
Common use cases for Chaos Engineering could be:
- Dependency chain-of-failure mitigation: What’s the impact on business services of a backend fault? How can it be tackled?
- Cloud migration: What happens when you migrate an on-premises service (with basically no network time) to the cloud?
- Disaster recovery: What happens when your data center goes down? Is the disaster recovery process working as expected? Do you meet disaster recovery guidelines?
- Observability verification: Is your observability platform set up properly? How long is the MTTR? Is the remediation process working as expected?
- Team training: Is your team ready to handle a failure? Are they trained properly to handle that situation? Is the escalation process working?
What are the benefits of Chaos Engineering?
Chaos Engineering allows increasing the reliability of the systems by:
- Reducing production incidents and identifying mitigations before they occur in production. Teams who consistently run chaos experiments have higher levels of availability than those who have never performed an experiment, as stated by Gremlin’s 2021 State of Chaos Engineering report.
- Decreasing MTTR (mean time to resolution), thanks to the increased awareness on how the system behaves in the event of a failure and better preparation in terms of people and processes. Gartner states that, by 2023, 40% of organizations will implement chaos engineering practices as part of DevOps initiatives, reducing unplanned downtime by 20%.
- Enabling faster cloud initiatives, thanks to the ability to measure the real impact of how services are impacted from the cloud migration.
How does Chaos Engineering work?
As previously mentioned, Chaos Engineering enables companies to compare what they think will happen to what actually happens in their systems. Running a chaos experiment means that you need to apply the scientific method to IT systems and not just run a random attack against a random system.
Chaos Engineering is usually implemented with a stepwise approach:
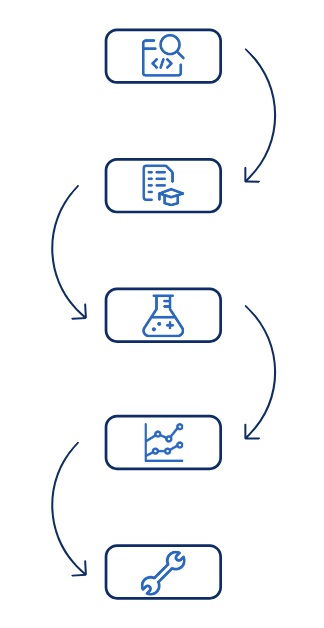
- Steady-state observation: Observe the system during its normal behavior and define the “steady-state” condition based on measurable KPIs (throughput, response time, error rate, etc).
- Formulate hypothesis: Create a hypothesis on how the system should behave if a failure condition affects it, such as a service shutting down, a 3rd party latency increasing by 2x or a whole Kubernetes cluster disconnecting from the network.
- Experiment: Design and perform an experiment to verify the hypothesis. Identify an experimental group, define the blast radius, inject the failure and collect data on the system under test.
- Analyze: Analyze experiment data and compare the results between the control group and the experimental group. Did the system behave as expected during the test? If not, why?
- Fix: In case the experiment showed an unsatisfactory behavior, fix it and replicate the test to verify it. If the experiment showed that the behavior is satisfactory, define a new test and extend the blast radius.
If not well planned and organized, Chaos Engineering may not provide the expected benefits or even be dangerous. In fact, the general recommendation is to start small (by limiting the so-called “blast radius”) and gradually gain confidence with all the tools needed to perform and analyze the experiments’ data before expanding its scope.
Starting small, fixing what does not work, and repeating the experiment, quickly adds up. This way the systems become better at handling real-world events which can’t be controlled or prevented. Thus accomplishing the goal of Chaos Testing.
Why Moviri introduces Chaos Engineering as a service offering?
Moviri constantly evolves its services catalog to allow its customers to adopt cutting-edge technology in the IT space.
We are pleased to announce that our Performance Engineering team added Chaos Engineering to its service portfolio.
Chaos Engineering integrates Moviri Design & Validation offering, allowing to further improve the value that Moviri Performance Engineering services bring to their customers. Moviri Chaos Engineering proposition features strong synergies with the existing services, providing a unified framework that can address a wide set of use cases.
Moviri Performance Engineering Services
- Design & Validation
Our performance engineering design and validation services help companies build high-performance architectures and services. We are experts in performance testing and tuning, chaos engineering, autoscaling, and right-sizing, from evaluation to implementation.
- Self-Driving Ops
We have built a distinct expertise in self-driving operations in production, such as AIOps, dynamic optimization, chaos testing, canary deployment and self-remediation, automatic discovery and real-time service mapping.
- Observability
The entire range of IT operations as they relate to performance engineering: performance monitoring, digital performance management, end-user experience management, IT performance analytics and visualization.
- Planning & Control
We use a performance engineering approach to solve the IT cost equation, helping customers with their capacity planning and management processes, IT resource utilization accounting, chargeback and cost controls.
As explained above, if the chaos experiment isn’t well planned and organized, it may cause more harm than good. The experiment needs to follow a strict plan and you need to start small. This is where the more than 20 years of expertise of Moviri’s Performance Engineering team comes into work.
Here are some interesting use cases in which Moviri experts can help businesses.
- How do you deal with steady-state in non-production environments? How can you perform a meaningful experiment if you don’t have meaningful traffic on your environment? A load test could be the answer. Moviri consultants can use an already existing performance test to artificially generate a steady-state and observe how the system behaves when a fault is injected. This approach is repeatable. The exact same steady-state can be replicated to re-run an experiment with different failures or with a bigger blast radius.
- What if you run an experiment and you realize there are blind spots in your observability platform? Or worse, what if the hole is in the remediation process? Moviri engineers could help extend your observability capabilities in terms of tools, people, and processes, to avoid this situation to happen in a production environment and impact customer experience.
- Chaos Engineering experiments may reveal an inadequate level of resilience that can be easily addressed by reconfiguring some of the components/layers of the architecture, without changing the code or having to add more cloud/infrastructure resources. In this case, Moviri experts can leverage Akamas AI-powered continuous optimization capabilities to maximize resilience and minimize costs without any manual effort.
We can help you implement a state-of-the-art performance engineering framework to deliver the best performance to your business.
Don’t wait any longer. Improve your service resilience now!
Performance engineering solutions
Discover our services and solutions:
- Peak demand events
- Kubernetes & microservices
- Agile, DevOps & CI/CD automation
- AI-powered performance engineering
- and more…

Categories
- Akamas
- Analytics
- Announcements
- Arduino
- Big Data
- Capacity Management
- Cleafy
- Cloud
- Conferences
- ContentWise
- Corporate
- Cybersecurity
- Data Science
- Digital Optimization
- Digital Performance Management
- Fashion
- IoT
- IT Governance and Strategy
- IT Operations Management
- Life at Moviri
- Machine Learning
- Moviri
- News
- Operational Intelligence
- Partners
- Performance Engineering
- Performance Optimization
- Tech Tips
- Virtualization
Stay up to date
© 2022 Moviri S.p.A.
Via Schiaffino 11
20158 Milano, Italy
P. IVA IT13187610152