Justin Martin
Senior Technical Solution Leader - Cerner
"IT Infrastructure Capacity Management requires a multifaceted knowledge about technology, business processes, and practice. Moviri's experts brought to Cerner knowledge about the tools, methodologies, and processes that helped with maturing the practice to an unprecedented level that still provides benefits to the storage, compute and network infrastructure capacity planning.”
Read more
Pablo Antolín
Product Manager, PayTV - Telefónica
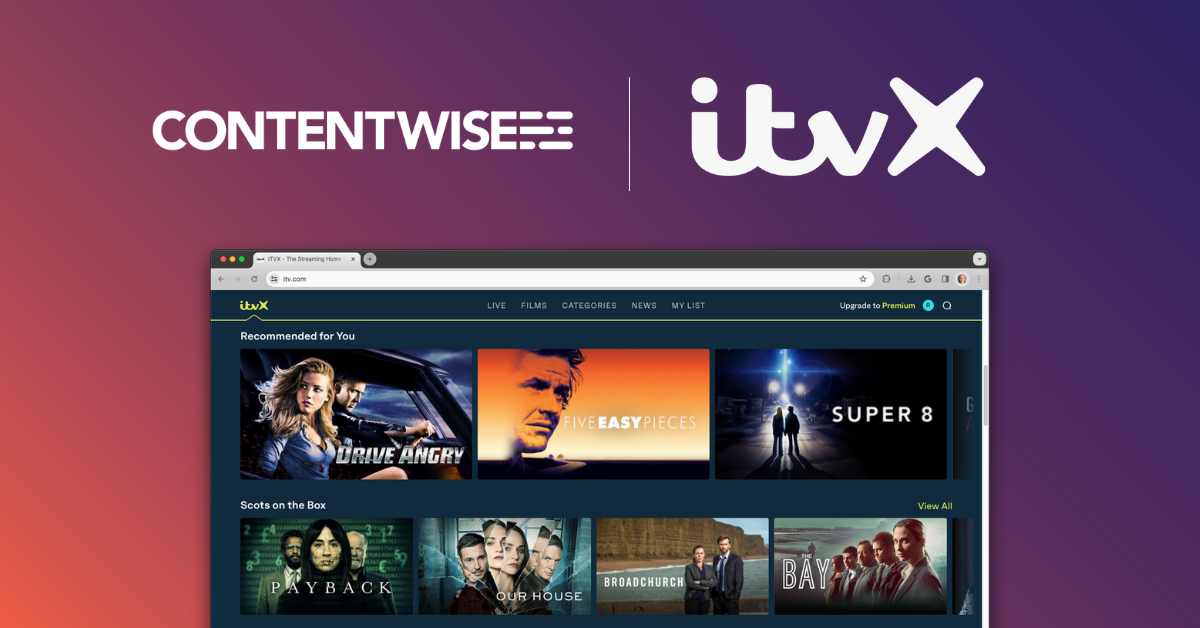
“Telefónica is changing the way users interact with our video products, following the principle of always placing them at the center of the experience. With the ContentWise solution, we can offer viewers personalized and simplified user experiences."
Read more
Massimiliano Mazzarolo
Chief Technology Architect - lastminute.com
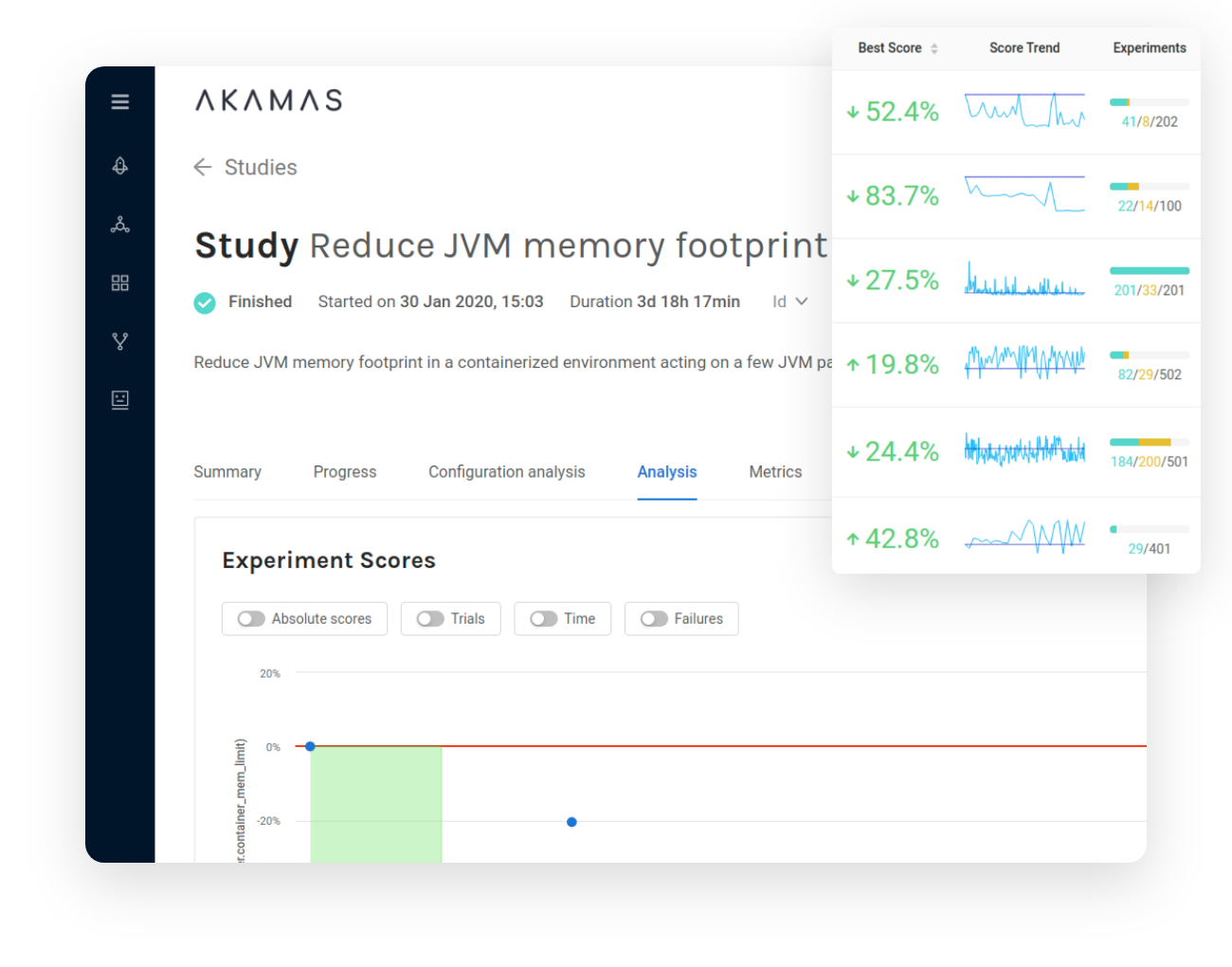
“Akamas AI allowed us to optimize our container-based Java services, significantly increase reliability under peak loads, and drive towards our cost-saving goals. AI-driven optimization by Akamas created a new competitive advantage for lastminute.com and better efficiency in our private cloud platform. Autonomous performance optimization is real and is here.”
Read more
Andreas Grabner
DevOps Activist - Dynatrace
"Application development and release cycles today are measured in days, instead of months. Configuration options of the tech stack continue to increase in scope and complexity, with dependencies that have become unpredictable.[...] Tools like Akamas allow us to help our organizations deliver exceptional performance while keeping an eye on resource consumption and costs."
Guillermo Paez
Product and Innovation Manager - Cablevisión
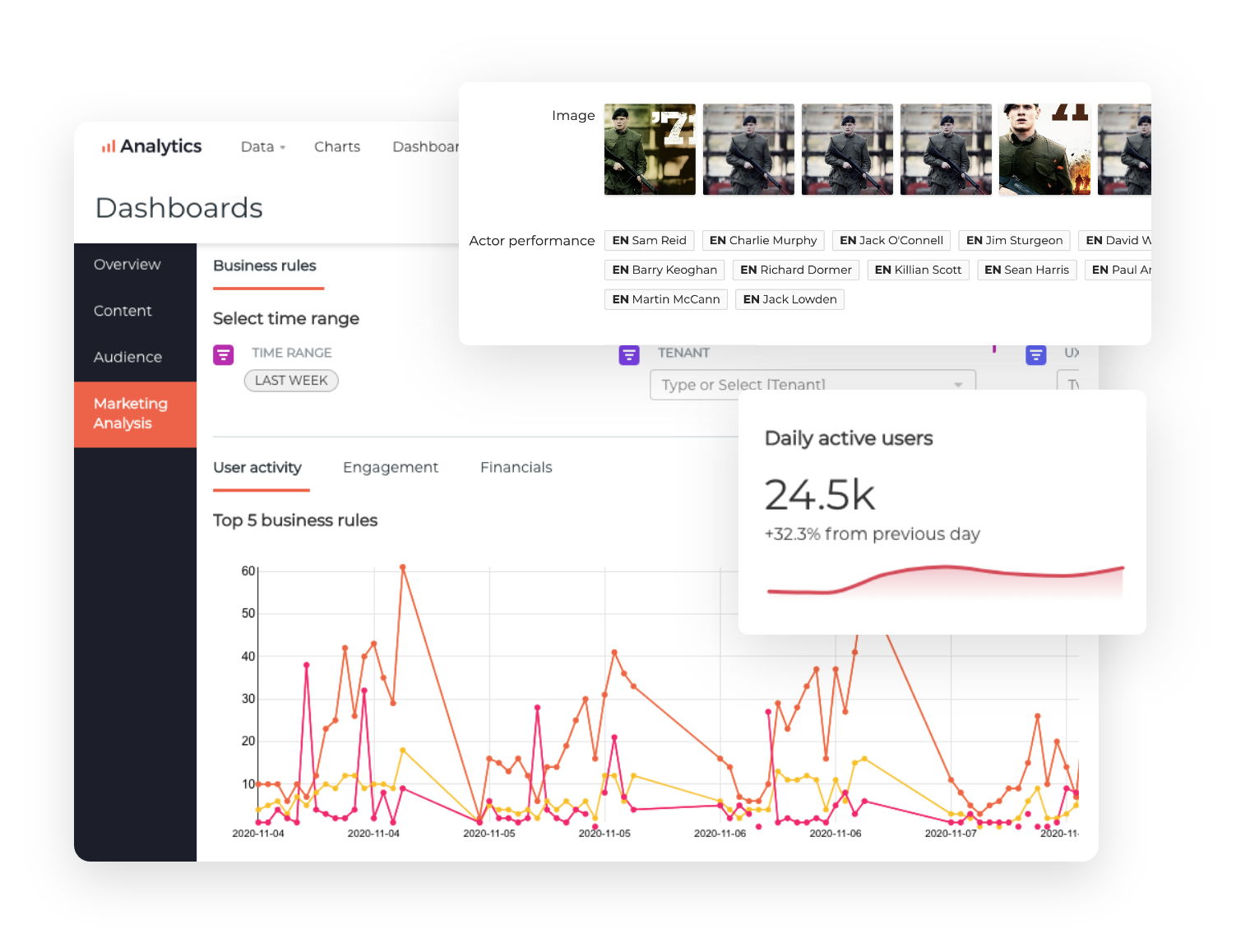
"Cablevisión customers are looking to enjoy a personalized TV experience. ContentWise expands our ability to deliver state-of-the-art personalized TV experiences, make our offering more attractive and learn about our subscribers preferences. It is the foundation upon which we are able to continue to enhance and extend our service offering."