Big Data, Capacity Management, Performance Optimization, Virtualization
Having an imPACt at CMG 2016
- By Stefano Doni
23 Dec
When your company tagline explains that it’s all about performance, you cannot possibly miss out on the CMG 2016 conference. The fact that this edition’s venue was at La Jolla, San Diego, made it all even more pleasant!
The temptation to go out with the board and get one wave in a Johnny Utah style was great, nonetheless the CMG imPACt agenda was so packed with top-notch speakers from Google, Microsoft, Facebook, .. Moviri!, that you could not have gotten any better excitement (for an engineer … anyway) outside the conference.
In this post you will get a quick overview of the sessions that we “movirians” held at the conference, and then a closer look at a selection (always a tough task) of the most interesting ones we attended.
Our Sessions
What really made us proud this year is that we had sessions based on the R&D efforts at Moviri (CPU Productivity, Containers and Big Data) and also based on our efforts on the field (Accounting and Chargeback training).
Over the past few years we have invested the time and brains of our best movirians into collaborations and long-lasting relationships with top universities, focusing particularly on solving innovative cutting-edge technology problems. We constantly rely on the fresh perspective of newly graduated students and we mix it up with our experience.
CPU Productivity: a New Metric for Performance Analysis
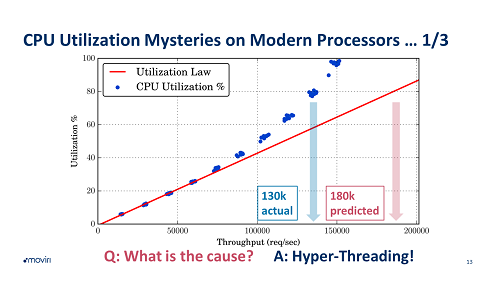
Have you ever used CPU Utilization to identify bottlenecks in your systems or to predict if your site has enough capacity to sustain the new marketing campaign (Black Friday, Christmas special deal , product launches, …) ? I suspect the answer is yes for 100% of us! The processor is the most critical resource in our systems and Utilization is the single most important metric used both to assure adequate service performance and to keep our IT footprint under control – both on premises and even more on the cloud.
But… there is a problem with the way CPU utilization metric works today: it was a perfect metric for systems created 15 years ago! Modern processors are significantly more complex than they were years ago, with the result that our beloved CPU Utilization is no longer measuring… the real utilization of your CPU!
The impact?
A real one: several customers engaged us with questions around why their business-critical service started to slow down… at 60% CPU utilization. You should have plenty of spare capacity, right? Well… not quite! At 50% of “utilization”, your CPU cores might well be at 80%, of the actual processing power they can deliver.
What can we do then? At CMG, we had the pleasure to present the result of our latest effort, a real research project we conducted with one of the leading Italian universities with a “simple” goal: define a new metric, which we called Productivity, which is able to estimate how much business transactions our customers can drive with their CPU. Measure the actual work a CPU is doing, and how much capacity is left in a much more accurate way.
So, what is the secret sauce behind Productivity?
We exploited a new class of performance metrics gathered directly from the CPU itself via the so-called Hardware Performance Counters, and added some machine-learning on top to come up with an estimation of the amount of work a CPU can perform.
We were extremely pleased to see such a crowded room at CMG! This testifies that the problem we addressed is hurting people managing IT performance & capacity, and we were glad to receive such a positive feedback from recognized performance experts of the field! We even managed to raise the interest of a top-tier processor vendor…
How to collect data … focus on Hadoop, Containers, Network
This session was a compendium of some challenges we have faced at companies around the world and what we are working on in our Labs:
Today’s datacenters are increasingly becoming more complex, to the point that you either end up feeling like you are starring in Star Trek’s episode “The Trouble with Tribbles” or you have to do something about it
Many of our customers that deal with Enterprise Capacity Planning are looking at new Hadoop initiative and asking themselves “What is it all about?” We presented some analogies to show how to address all the little critters in the Hadoop ecosystems
Next, we addressed what to do for Containers
And last an overview of a systematic approach to performing Network Capacity Planning.
Accounting and Chargeback
During this 2 hours training session, we looked at the reasons behind setting up an Accounting and Chargeback process, the challenges, and the benefits it can bring to your organization
As part of the 3 components of the ACB process
We focused on a prescriptive workflow to make the process repeatable and some of the tips on how to get it right the first time.
On December 13th 2016 we held a webinar on the same topic.
CMG Session Highlights
Facebook: Managing Capacity and Performance in a Large Scale Production Environment
Facebook is known for tackling big engineering challenges, so when I sat down in the room I had high expectations from this talk. I have to say that Goranka Bjedov, head of Capacity Engineering, delivered an outstanding and super interesting talk! Doing capacity planning myself for years, I was eager to learn how capacity is managed in a leading and innovative web company, and compare with our practices in the enterprise.
So, what did I discover?
I think the main theme was focus on efficiency: Facebook capacity team makes great strides to squeeze every CPU cycle out of their machines! They are not afraid of developing custom tools that provide very granular (1 second resolution!) and detailed metrics about the full stack (up to the CPU performance counters). How is site capacity managed? Similarly to other web scale companies (e.g. Netflix), Facebook approach is to use live production traffic to stress systems and understand their maximum capacity – and this process is automated and performed multiple times per week!
Goranka concluded the session by stating her future goals: being more proactive! This is funny: even with top-notch practices and highly talented engineers, there is always room to improve in capacity management 🙂
Flying Two Mistakes High: a Guide to High Availability in the Cloud
Another great talk at CMG was Lee Atchison’s (@leeatchison) one. Lee is Principal Cloud Architect at New Relic, and was previously responsible of designing core cloud services at Amazon Retail & AWS. So, who could better explain how to architect cloud systems for high availability and scalability?
Are you on the cloud? You think capacity planning is no more required, as you can always automatically scale and be always online?
Well, quite the opposite! Lee explained very clearly how capacity planning is not only mandatory in the cloud, but for certain aspects even more important to understand how to keep your service up. The cloud is full with new, “invisible” bottlenecks you don’t expect and sometimes you can also hardly measure with current approaches. Plus, you need to think carefully about HA in your capacity plan too!
Great work Lee, thanks for sharing such valuable insights!
Implementing Metrics-Driven DevOps: Why and How!
I really loved this talk by Dynatrace Andreas Grabner! (@grabnerandi) Many companies are (rightfully) adopting DevOps to bring down silos and increase the speed of delivery, reducing time to market and bringing features in the users’ hands faster and faster.
But how does performance and efficiency fit into this picture? Unfortunately, it is often left out in the cold! Continuous integration in the software development cycle typically consider just functional testing. Andreas showed what could be the impact of that, especially if you are on the cloud: a seemingly innocent code release might suddenly increase your cloud footprint – and your monthly bill – by 4x! If you don’t include performance and cost efficiency KPIs in your pipeline, you might discover the bad news weeks or months after the guilty release happened: almost impossible then to figure out which one was the culprit…
So how to prevent this from happening? The key is considering performance testing and benchmarking as a first-class citizen in your software development pipeline! The benefits? Not only preventing huge and unexpected cloud bills, but also establishing a performance/efficiency/scalability culture already in the dev phase, which is critical to deliver successful but also lean and cost effective products!
Conclusions
With transformative trends like DevOps and the rise of Cloud adoption, Big Data and Containers, IT is facing significant new changes: how do you manage them from the capacity and performance perspectives? Lots of established practices need to change to account for new delivery processes, technologies and pricing models.
Capacity Planning and Performance Management are not going away – quite the opposite! They are becoming more and more important to ensure good service quality, keep the IT cloud bills in check and enable safe IT transformation towards future architectures.
Enough with paddling. Pop-up, and start pumping your board!
We would really love to hear from you: if you have any questions or comments, please use the comment session below.
Anyway, you can stay up-to-date with our further developments and results by filling up the form at the top-right corner of this page.
Categories
- Akamas
- Analytics
- Announcements
- Arduino
- Big Data
- Capacity Management
- Cleafy
- Cloud
- Conferences
- ContentWise
- Corporate
- Cybersecurity
- Data Science
- Digital Optimization
- Digital Performance Management
- Fashion
- IoT
- IT Governance and Strategy
- IT Operations Management
- Life at Moviri
- Machine Learning
- Moviri
- News
- Operational Intelligence
- Partners
- Performance Engineering
- Performance Optimization
- Tech Tips
- Virtualization
Stay up to date
© 2022 Moviri S.p.A.
Via Schiaffino 11
20158 Milano, Italy
P. IVA IT13187610152