03 Jan

In the age of virtualization and cloud computing are Organizations able to provide business services every time their customers expect it, even if a Disaster happens?
I asked myself this question as I perceive a false sense of security from many of our customers. This misperception is the product of considering virtualization and cloud computing like some kind of magical formula that offers 100% availability – anybody knows that that is almost impossible!
The very first question to be answered in Business Continuity Management is which are the most vital services in keeping the business alive? That can then be translated and developed into a through understanding of the consequences of being far from 100% availability and therefore put in place appropriate countermeasures.
A Business Impact Analysis (BIA) is still the best high-level instrument to answer the question.
It allows, through a top-down approach, to identify qualitatively and quantitatively the impact the Organization would experience in case of a Disaster and to understand how to manage critical and non critical assets.Where to start from? A consolidated methodology to evaluate how much a Business Service is critical should be shared between IT and business management, taking into account several factors such as potential economic losses due to SLAs violations, missing Compliance or mandatory legal requirements, brand-image damages, etc. Don’t forget to put the focus on information, data and services rather than each single asset. You, like your customers, should be more concerned with information rather than the hardware or software where it resides.
Define Critical Services
What is unacceptable for the Organization (e.g. economic damages greater than $100,000, a service interruption for a number of customers greater than 1000, etc…) is defined as critical. A multi-dimensional matrix helps in defining criticality for each Business Service combining different factors (the next example considers two dimensions).
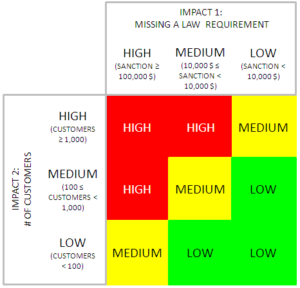
Defining RTO and RPO
Given a Services classification, two parameters are evaluated for those belonging to the critical class:
- the Recovery Time Objective (RTO) is the acceptable amount of time to restore the service
- the Recovery Point Objective (RPO) is the acceptable amount of data, measured in time, that can be lost.
Sizing RTO and RPO
Budgets and Acceptable losses are two typical drivers used in RTO and RPO sizing. The next example refers to the sizing of an RTO value.
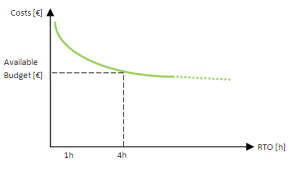 In the left figure, Budget is the driver. The Organization made a strategic investment of a given amount of money to recover the Services, and this guarantees an investment opportunity that ensures service recovery within four hours.
In the left figure, Budget is the driver. The Organization made a strategic investment of a given amount of money to recover the Services, and this guarantees an investment opportunity that ensures service recovery within four hours.
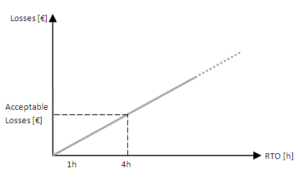
In the right figure, Acceptable Losses is the driver. Assuming a linear relationship between losses and recovery time (the greater the service downtime, the greater are the losses) the Organization made a different strategic choice fixing the losses upper bound.
What to do now?
The challenge in Security is usually finding a trade-off between the costs of accepting a risk and the expenses to avoid the risk itself. Are you managing risks introduced by new technologies? If the answer is no, a Business Impact Analysis should be a priority.