Analytics, Data Science, IT Operations Management, Machine Learning
Anomaly Detection with Machine Learning
09 Feb
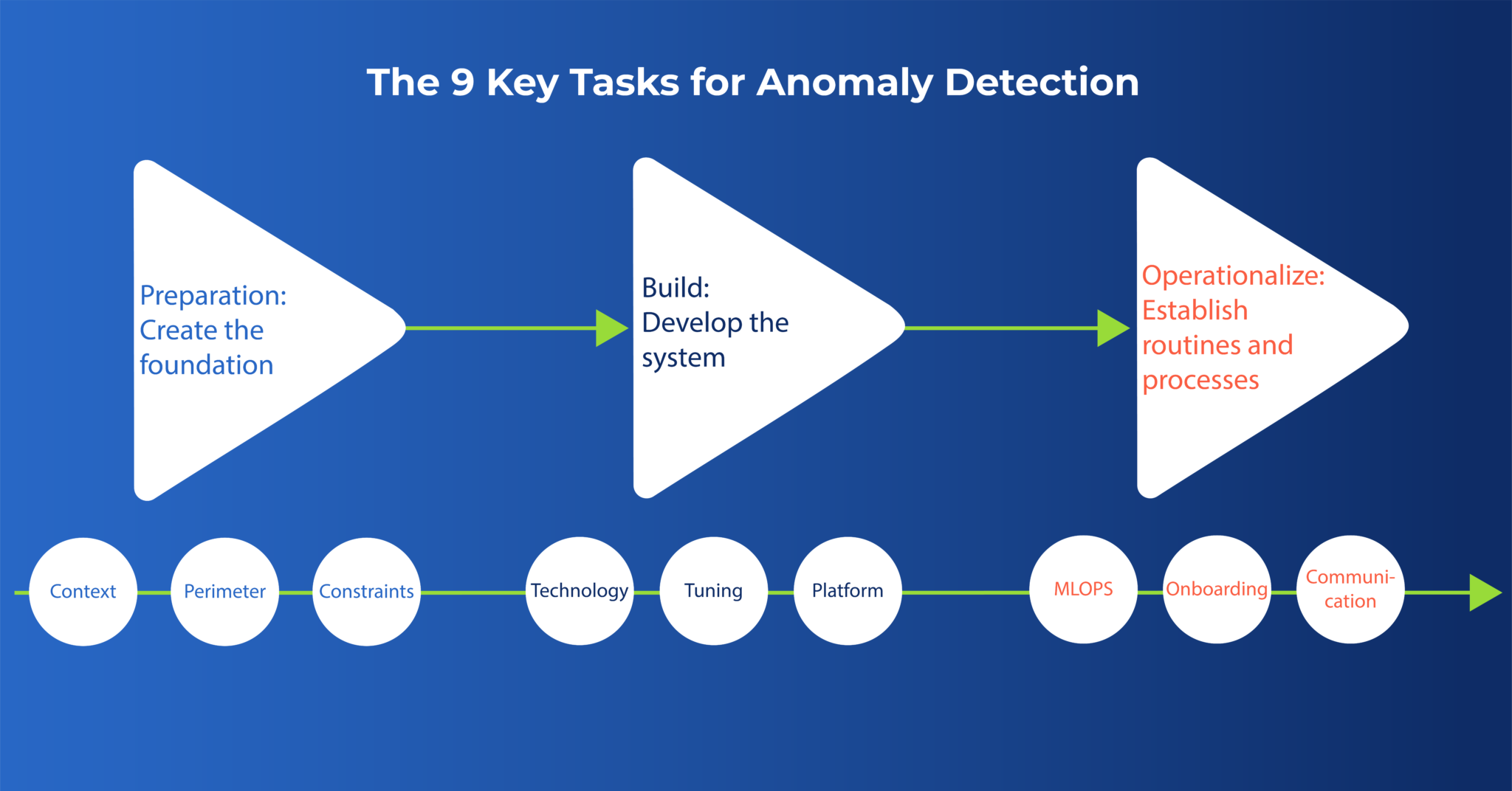
The 9 key tasks that technology leaders must fulfill to implement a successful enterprise anomaly detection system.
Regardless of which machine learning methods one uses to perform anomaly detection — and the literature offers plenty of them — analysts usually run into trouble when it comes to deploying such methods in an enterprise business environment. Resource allocation and usage demands, as well as latency, performance and scalability requirements, are often underestimated. This can create major issues and complexities that data scientists and data engineers must deal with, when designing an anomaly detection pipeline.
In this article, we offer a practical, high-level blueprint that digital and technology executives can follow to make sure anomaly detection systems fulfill their innovation and value-creation promise.
What is Anomaly Detection?
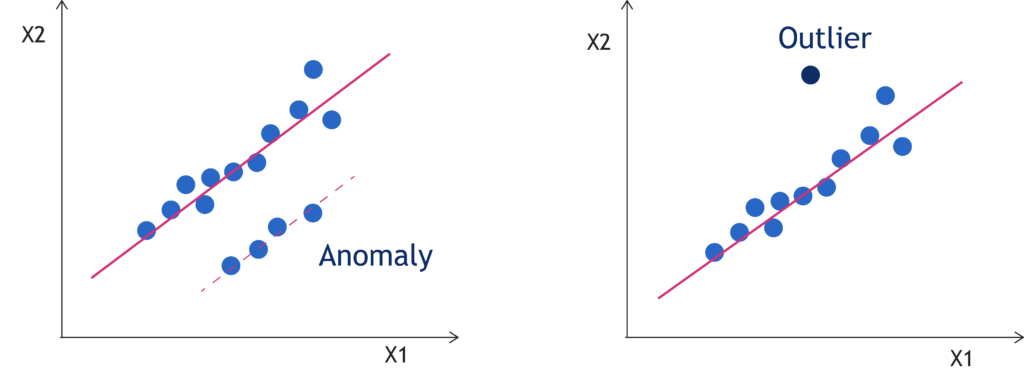
In this article, anomaly detection refers to a group of machine learning techniques whose aim is to spot anomalies in a set of observations, usually to halt unwanted behaviors in your systems. The term anomaly is often used as a synonym for outlier. There is, however, a subtle but crucial difference between the two.
An outlier is an event that, given a certain data distribution, is unlikely to happen, a low probability occurrence. An anomaly, instead, is an event that is virtually impossible to explain, given the same data distribution.
While outliers are accidental and can be caused by chance, anomalies have deeper roots and can be traced back to causal conditions or events. And to the extent that there are specific mechanisms that generate an anomaly, the job of anomaly detection, especially in a business context, is to discover them.
In this sense, “traditional” anomaly detection has significant limitations. The most common approaches to anomaly detection are burdened by computational complexity. Many need training to learn patterns from the data, continuous updating, fine-tuning and ongoing maintenance, all of which consumes an enormous amount of resources.
And what about false positives, changes to data structure, low user-friendliness and IT team dependencies typical of the most common approaches?
Anomaly detection has great potential, if done right. Organizations need to rethink their approach, by building systems that can overcome these obstacles and perform efficiently, while remaining lightweight and flexible. Are you sure your strategy and processes are correctly set up to deliver the benefits you expect from investing in anomaly detection?
The most common approaches to anomaly detection are burdened by computational complexity. Many need training to learn patterns from the data, continuous updating, fine-tuning and ongoing maintenance, all of which consumes an enormous amount of resources.”
Anomaly Detection: The 9 Key Tasks
Knowing which book you should take from the shelf is not easy. Every algorithm must be adapted to tackle any major challenge and managed at scale within the constraints and specific scope of your enterprise setting.
We have developed a succinct executive guide to help you set a blueprint to unlock the full value of anomaly detection with machine learning. This blueprint involves 9 distinct critical steps, organized in 3 main stages:
- Preparation. Create the foundation for anomaly detection success.
- Build. Develop the system and infrastructure you need to achieve it.
- Operationalize. Establish routines and processes to deliver ongoing value.
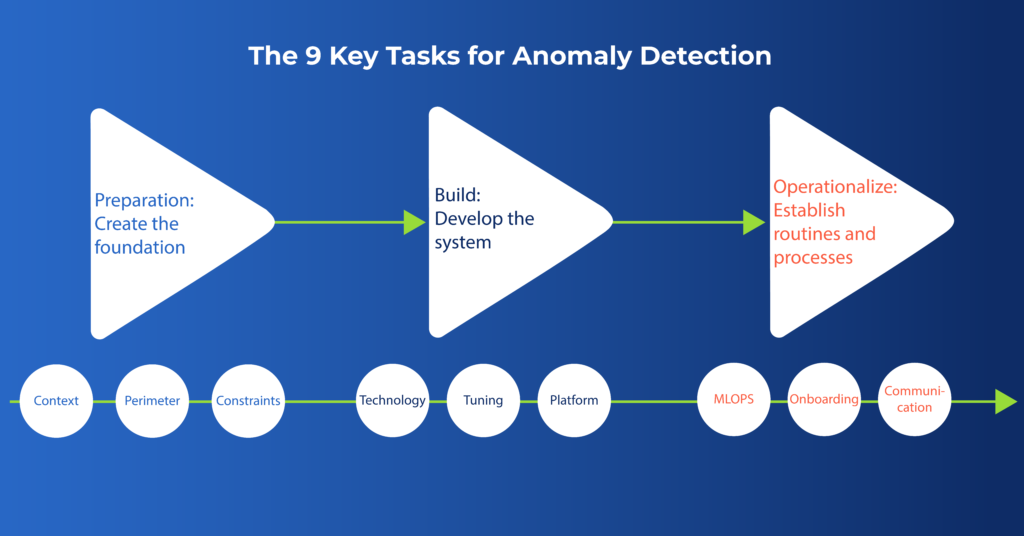
Preparation: Create the Foundation
1. Context (Process Analysis, Anomaly Types, Parameters)
With every analysis problem, understanding and codifying the context is an essential first step. This is all the more true in anomaly detection systems. The context enables us to understand which parts of the process and which parameters we should focus on.
Machine learning needs to be guided so it can accomplish the goals described by business requirements. What types of anomalies are we after? How does the underlying process work? What are the key inputs and outputs that we want to codify?
Another vital question in this early stage of analysis is which variables are good target candidates for spotting anomalies. For example in a typical application use case, such as transaction monitoring, shall we focus on the number of outliers? On the timing with which they occur? On empirical statistical events? Do we have all the necessary data?
This step is a fundamental one as it enables analysts to codify and expand domain knowledge and improve your analysis.
2. Data Assessment (Frequency, Volume, Updates)
With a solid mapping of the context, we can move on to data. First, we must clearly identify the source data sets and streams and, second, ensure they are complete and correct. This is not a trivial task, as it typically requires the contribution of a variety of organizations and stakeholders, such as process owners, data owners and governance. On the technical side, IT system engineers, data scientists, data engineers are involved in assessing the time series length, frequency, volume and the right pipelines and infrastructure that are required to reliably feed your anomaly detection system.
For example, anomaly detection is highly dependent on the frequency and nature of data updates, so it is important to map the processes responsible for data updates, how often which data is updated, and specifically which parts of a data set are updated.
3. Constraints (Perimeter, Real-Time, Granularity, Operations Requirements)
In addition to context and data, anomaly detection system designers must consider a variety of constraints. There is no such thing as a free lunch, and there is no algorithm that performs equally well under all conditions. Each algorithm works best under certain assumptions, which may be hard to validate in some conditions and hence need to be well understood before you start. That’s why we need to clearly design the perimeter within which anomaly detection algorithms must work.
Sometimes constraints come from the very definition of the anomaly detection’s targets or user requirements. For example, whether we have a 99% anomaly detection target in a transaction monitoring system or a 50% target makes a structural difference in the system design.
As important are “external constraints” (i.e. not related to the data and algorithms themselves), such as usability constraints. How do users need to be notified about anomalies? How often? Through email, the web, app notifications or a combination of channels? Back to the transaction monitoring example, if anomalies are related to channel payment failure, it may be pointless to notify the process manager once a day, if the goal is to ensure business continuity. Depending on the application, we may need to detect anomalies every 10 seconds, 1 minute, or 1 day.
There is no such thing as a free lunch, and there is no algorithm that performs equally well under all conditions.”
Build: Develop the System
4. Machine Learning Model (Algorithm, Model, Approach)
Once our anomaly detection foundation (context, data and constraints) is in place, we are ready to start work on selecting the best algorithms and building models. Again, literature can help, but knowing which book we should pick from the library is not easy.
Let’s take rare events, as an example. By definition, an anomaly is an event that represents a significant departure from the usual, and therefore, anomalous occurrences may be few and far between. Occasionally, we may not even know what an anomaly actually looks like. Machine learning algorithms may have to account for class imbalance problems or determine an anomaly’s features autonomously.
Trends and seasonality are another example. Many algorithms label data points as anomalous if they exceed some predefined thresholds. Unfortunately, these algorithms fail when data presents trend behavior and/or seasonality (think of sales data that peak before year-end and decrease right after). These data features force data scientists to design ad-hoc models.
5. Technologies (Software, Platforms, Pipelines)
To design an environment that orchestrates all the components of the system and guarantees the performance, you need to find the right combination of software tools, architecture, and pipelines: the domain of data engineering.
Every link in the chain must work flawlessly and smoothly. But with an overwhelming choice of commercial and open source platforms for storage, pipelines, ingestion, databases etc.selecting the right components is crucial. For example, we can opt for a cloud solution, instead of on-premise. Or a hybrid one. But how shall we determine which of several components to run in the cloud? How can we assess the feasibility and performance of the system?
This is true whether the anomaly detection system is designed from scratch or built on an existing architecture. In every case, it is important to start from our goals and requirements and work our way backwards to find the best solution.
6. Tuning (Testing, Accuracy Validation, Exception Management)
An anomaly is almost always the result of a combination of factors and their interactions. For this reason, systems that rely on parameter thresholds or empirical observation to determine anomalies usually underperform machine learning-based approaches. These approaches however introduce more complexity and nuance. Black and white give way to shades of gray.
An anomaly can occur when a certain pattern of factors takes place. Alternatively, an anomaly can be so considered depending on the context and environment in which it happens, or when a certain sequence of events happens in a specific order, and not in another.
For example, when a piece of industrial machinery fails, you typically register changes in the data coming from several sensors, each of which may not be by itself sufficient to detect an anomaly. It is their combination that signals an anomaly correlated with the failure.
In some situations, it is vital that only the most consequential anomalies are labelled as such (think of costly industrial failures), while in others missing a single anomaly is one too many (COVID testing is an example). The key is to model the context’s complexity to define appropriate scales (e.g. criticity scales), so that you can correctly prioritize the most critical anomalies and focus your attention on root causes. Different problems need different tuning and optimization approaches.
Operationalize: Establish Routines and Processes
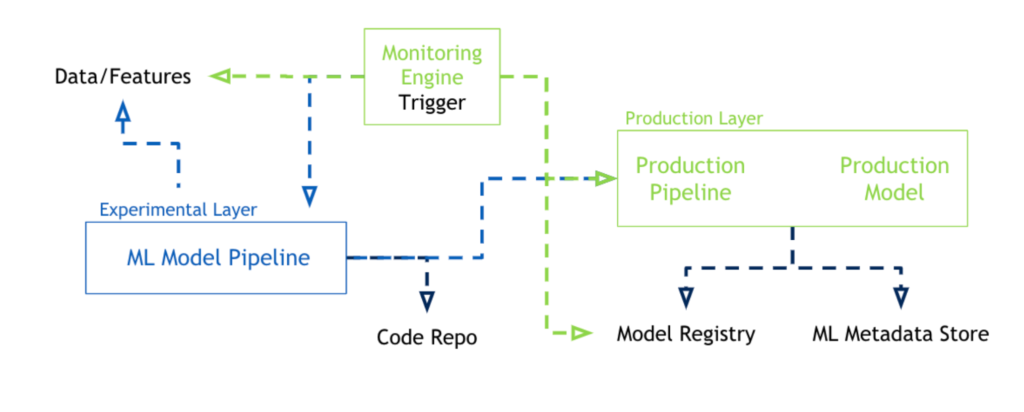
7. MLOps (Maintenance in ML Operations, Continuous Improvement, Maintenance)
Generally speaking, MLOps is a framework designed to orchestrate, automate and scale your machine learning-based anomaly detection operation. Whether an MLOps practice has already been deployed at your company or not, you will have a hard time harnessing the full value of an enterprise anomaly detection program without the support of a well-developed MLOps process.
MLOps activities include automation of machine learning development steps (e.g. data extraction & preparation, model training & evaluation, performance monitoring…), service management (e.g. maintenance, monitoring of health-related metrics like response time, execution time, number of predictions, etc.) and data drifting.
The real world changes every day, and what is anomalous today may be normal tomorrow (e.g. changes due to the pandemic). MLOps ensures that your models are continuously aligned with changing conditions, as well as with changing requirements from stakeholders.
8. Onboarding (Stakeholders, Users, Change Management, Training)
Involve your stakeholders, understand their needs and make them happy. Easy, isn’t it? Well, actually, yes, if we are fully aware of who they are and of their different roles, expertise and expectations.
Think for example about an IT project manager, or the final business user. Or the business user’s manager. Or the owner of the process targeted by the anomaly detection systems. Every individual involved in the project is, in fact, a stakeholder. We must endure that their expectations are met and communicate with appropriate levels of detail and context.
Keep them updated, show them concrete results, deliver granular deliverables throughout the duration of the project. If you only interact with stakeholders at major checkpoints, you risk discovering that minor gaps in understanding and expectations have widened beyond repair. Guide stakeholders towards the end result, keeping in mind each individual’s perspective.
Because it is important to make all of them happy (as it is, after all, for any of our customers) so that they use your system and bring the expected impact to fruition.
9. Communication (Visualization, Reporting, Alerting, Priorities Evidence)
The more advanced a method, the harder it can be to interpret the results for non-experts. If stakeholders don’t understand the behavior and output of the anomaly detection system, their engagement level decreases. It is our responsibility to make sure they do.
But how? It helps to stick to simplicity and habit, by leveraging as much as possible the tools, systems, visualizations and language that stakeholders already use. In those cases when this is not possible or advisable, we need to involve stakeholders step by step in developing communication, visualization and alerting interfaces, while steering clear of unnecessary technical details.
For example, if you are talking to a data engineer trying to define the project’s goals, you must make an effort to answer their questions even if a definition of the outcomes is still foggy. This will help both of you. On one hand it will make it more likely that the results come close to your requirements and, on the other, it will give shape to the details in your mind.
Alternatively, if you’re presenting to somebody who lacks your data science expertise, focus on the results that anomaly detection can deliver, like detecting and ranking 10x more low-false positive anomalies automatically in less time. Regardless of which magic algorithm or how many lines of beautifully written PySpark code you wrote, the appreciation of the value delivered by anomaly detection will hit home, finally.
Guide
Anomaly Detection with Machine Learning
In this paper, we offer a practical, high-level blueprint that CTOs can follow to make sure anomaly detection systems fulfill their innovation and value-creation promise.
Find out more about the 9 key tasks that CTOs must fulfill to build an enterprise anomaly detection system.

Categories
- Akamas
- Analytics
- Announcements
- Arduino
- Big Data
- Capacity Management
- Cleafy
- Cloud
- Conferences
- ContentWise
- Corporate
- Cybersecurity
- Data Science
- Digital Optimization
- Digital Performance Management
- Fashion
- IoT
- IT Governance and Strategy
- IT Operations Management
- Life at Moviri
- Machine Learning
- Moviri
- News
- Operational Intelligence
- Partners
- Performance Engineering
- Performance Optimization
- Tech Tips
- Virtualization
Stay up to date
© 2022 Moviri S.p.A.
Via Schiaffino 11
20158 Milano, Italy
P. IVA IT13187610152